One of our Senior Software Engineers (Dave Edwards) picked up a spike to investigate making one of our Cosmos Dbs region resilient. The result was a very detailed wiki and set of test repos which I’ve summarized on this blog.
What are we looking for?
The Cosmos Db in question supports a business critical app which needs to be immune to Azure regional outages. Looking at the Global Distribution Overview from Microsoft, some bold statements are made.
Unlimited elastic write and read scalability.
99.999% read and write availability all around the world.
Guaranteed reads and writes served in less than 10 milliseconds at the 99th percentile.
All this looks great but how to implement it and at what cost?
Regions - How Many and Which ones?
Microsoft does recommend using azure paired regions but, on recommendation of a infrastructure partner, we have two express routes setup for two regions (which are not region pairs) so we’ve stuck with that.
Single Or Multiple Region Writes?
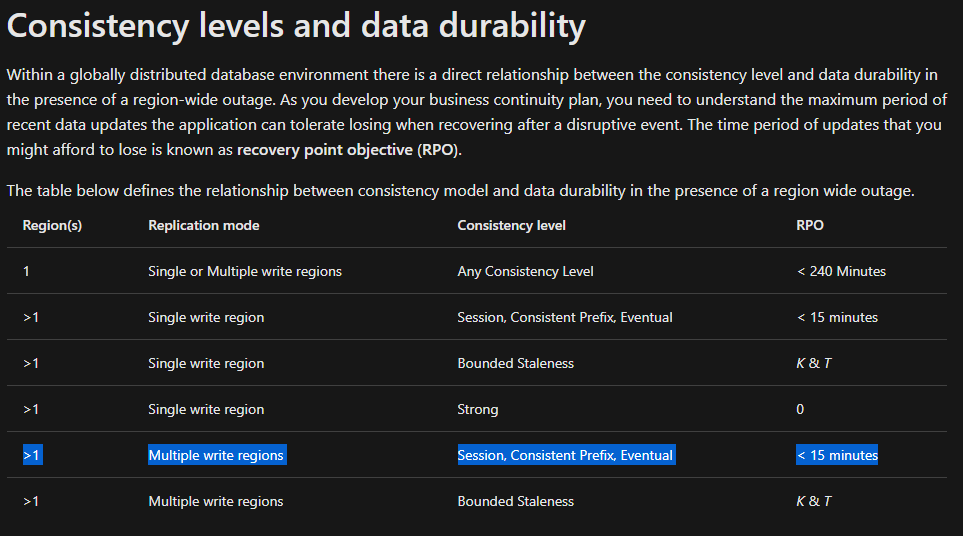
This decision was lead very much by business requirements i.e. an RPO1 of 0 and a RTO2 of 15 minutes meant that we should go with a single write region with strong consistency. I screen shotted the image below from Consistency Levels - MS Docs (the documentation is subject to change so took a screen shot to capture as is).
Client Configuration
In our case all the clients are stateless Azure Function Apps which means they to can be deployed multi-region (the same two as the CosmosDb) and configured with a simple setting to use the Cosmos Db in their region…
"CosmosDb:PreferredRegion": "West Europe"
With a single write region, conflict resolution seems to be something that the clients don’t have to worry about.
Zonal Redundancy
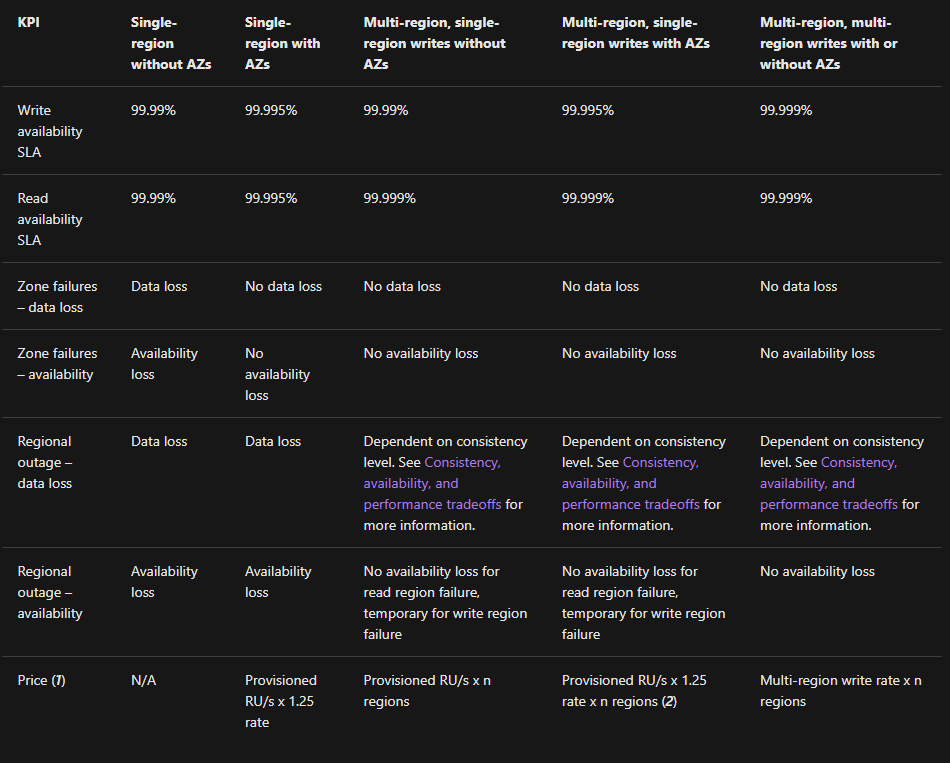
The Microsoft documentation here just doesn’t make sense (see below taken from Availability Zone Report). How can you have no availability loss on a zonal outage without zonal redundancy? We err’ed on the side of caution here and when for Zonal Redundancy.
Automatic vs Manual Failover
Automatic was an easy choice here, we also decided to stay on the new region post failure.
Tests
Dave created a series of tests with the above configuration simulating a region outage by temporarily configuring a manual fail over. He built a FunctionApp with the following endpoints and deployed it in the same two regions as the Cosmos Db (configured to use the Cosmos Db in their region).
- Basic write endpoint, to write a given payload to Cosmos
- Basic read endpoint, to return a document with a given ID
- Repeated write endpoint, to perform 100 updates to a given Cosmos document and report back the Cosmos latencies and RUs
- Repeated read endpoint, to perform 100 reads of a given Cosmos document and report back the Cosmos latencies and RUs
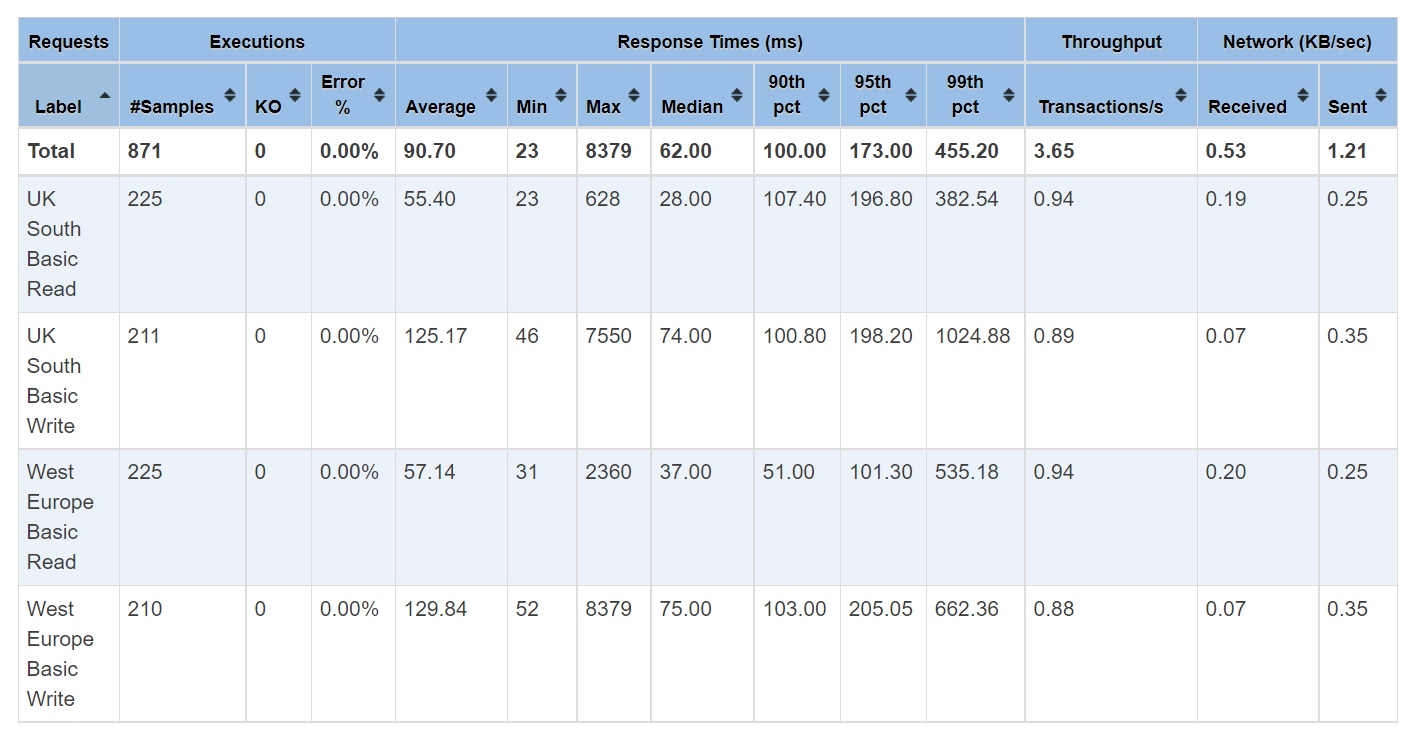
The tests culminated in a series of Jmeter tests to check for latencies during a fail over. The results of the West Europe to UK South failover are below (to give you an idea of performance).
Summary
From Dave: -
There were zero request failures during these tests, verified through both JMeter report and Function App metrics in the Azure Portal. This would suggest that any availability loss will present itself as at most a “blip” to users, with any request retries then succeeding. Could be worth repeating these tests with higher request frequencies to explore this further. There was a limited effect on latencies during the failovers, with only an isolated 1-second period in the middle of the 60-second failover period where response times spiked
So, it looks like this configuration will meet our needs and is relatively straightforward to implement; the clients don’t need to be super-aware only a configuration tweak is needed. There is a cost implication, as we’re effectively doubling up on RUs3 but why wouldn’t there be?
-
Recovery Point Objective, represents the time period of updates that you might afford to lose when recovering after a disruptive event (in this case a region-wide outage). ↩
-
Recovery Time Objective, represents the time required for an application to fully recover after a disruptive event (in this case a region-wide outage). Originally on the Microsoft documentation this was 0 but it has since been removed, something we will take up with Microsoft. ↩